深度学习是伴随着云计算和大数据时代发展起来的,理论知识其实早已经在很多年前就已经有研究,鉴于当时计算能力的有限,所以深度学习才被冷落。
深度学习是机器学习中一种基于对数据进行表征的学习,观测值(如图像)可以使用多种方式来表示,如每个像素强度值向量,或者抽象为一系列边、特定形状区域等。其好处就是用非监督或者半监督的特征学习和分层特征提取高效算法来替代手工获取特征。
神经网络
1.神经元
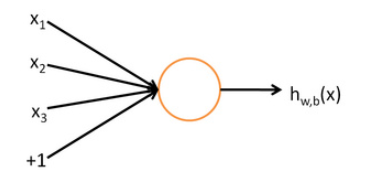 这其实就是一个单层感知集,其输入是由$x_{1},x_{2},x_{3}$和+1组成的向量,其输出为:$h_{W,b}(x)=f(W^\mathrm{T}x)=f( \sum_{i=1}^{3} W_{i}x_{i} + b )$,其中f是一个激活函数。
这其实就是一个单层感知集,其输入是由$x_{1},x_{2},x_{3}$和+1组成的向量,其输出为:$h_{W,b}(x)=f(W^\mathrm{T}x)=f( \sum_{i=1}^{3} W_{i}x_{i} + b )$,其中f是一个激活函数。
2.人工神经网络
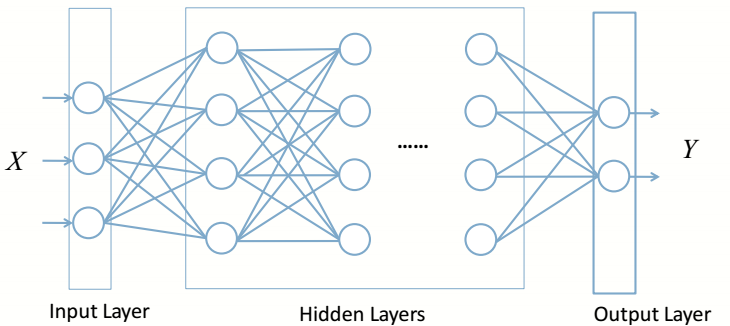 人工神经网络就是多个神经元的级联,上一神经元的输出事下一级神经元的输入,而且信号在两级的两个神经元之间传播的时候需要乘上这两个神经元对应的权值,层与层之间的神经元以全连接的方式连接在一起。
其中包含一个输入层,一个或者多个影藏层,一个输出层,如果影藏层的层数大于1层的话,就可以称为深度神经网络(DNN)了。
人工神经网络就是多个神经元的级联,上一神经元的输出事下一级神经元的输入,而且信号在两级的两个神经元之间传播的时候需要乘上这两个神经元对应的权值,层与层之间的神经元以全连接的方式连接在一起。
其中包含一个输入层,一个或者多个影藏层,一个输出层,如果影藏层的层数大于1层的话,就可以称为深度神经网络(DNN)了。
3.异或问题
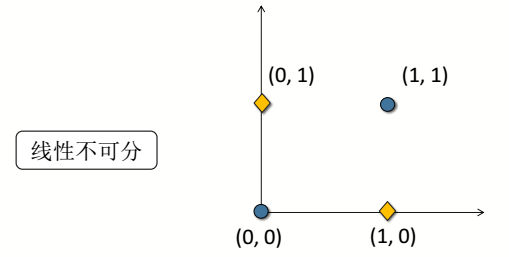 我们知道把向量做无限次的线性变换,依然是线性不可分的,所以我们要做一个非线性变换,就是在更高维的空间来做分类,神经网络是如何解决异或问题的呢?答案就是激活函数。
我们知道把向量做无限次的线性变换,依然是线性不可分的,所以我们要做一个非线性变换,就是在更高维的空间来做分类,神经网络是如何解决异或问题的呢?答案就是激活函数。
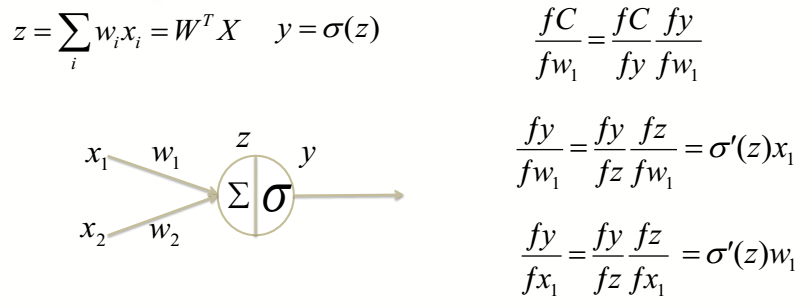 如图神经元:$\sum$ 就是做线性变换,对不同的输入进行求和、聚集,而$\sigma$ 做的就是非线性变换,将低维数据进行压缩、扭曲和变形,使其表达能力更强,表示更抽象。
如图神经元:$\sum$ 就是做线性变换,对不同的输入进行求和、聚集,而$\sigma$ 做的就是非线性变换,将低维数据进行压缩、扭曲和变形,使其表达能力更强,表示更抽象。
4.万能近似定理(universal approximation)
万能近似定理(universal approximation theorem)(Hornik et al., 1989;Cybenko, 1989):一个前馈神经网络如果具有线性输出层和至少一层具有任何一种“挤压”性质的激活函数(例如logistic sigmoid激活函数)的隐藏层,只要给予网络足够数量的隐藏hexo单元,它可以以任意的精度来近似任何从一个有限维空间到另一个有限维空间的Borel 可测函数。
有了万能近似框架,但是现实是我们没有万能的数据集与万能的优化函数来求的参数,还有可能因为过拟合而学习到了错误的函数。
5.softmax层
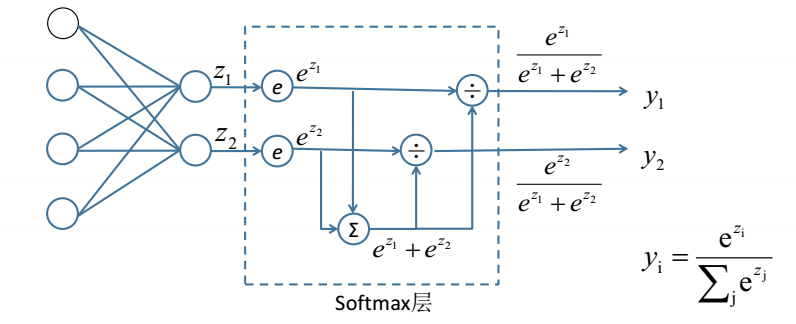 softmax作为分类任务输出的最后一层,在很多网络结构中都用应用。原理与公式参考图示。
softmax作为分类任务输出的最后一层,在很多网络结构中都用应用。原理与公式参考图示。
DNN
Dnn是深度学习的基础,Dnn其实就是隐藏层数比较多的一种神经网络,层与层之间都是全连接的。 DNN学习的数学原理参考博客反向传播与梯度下降
1.DNN的思考
神经网络的结构越深,表达能力越强,泛化能力越好,那么如何能训练一个很深的神经网络?
神经网络的优化算法是梯度下降,如何训练才能避免陷入检差的局部最优点?
2.神经网络的问题
1、梯度消失,网络结构很深的时候,每层反向传播都会乘上激活函数的梯度,而sigmoid函数的梯度最大值是1/4<1,多次乘一个小于1的数会趋向0,所以梯度消失。解决方法有几种:
- 使用Relu作为激活函数
- 人工增加数据量 (叠加噪声)
- 随机初始化参数 (随机正交矩阵,高斯截断正态分布)
- 使用预训练
2、梯度爆炸 在RNN中常会出现,因为反向传播过程中,state会共用W,所以会导致W会随着时间而连乘,如果W的值都大于1,则会梯度爆炸,如果小于1,则会梯度消失,解决梯度爆炸的方法是梯度裁剪,即,当梯度大于某一个阈值的时候,就强行将其限制在这个范围之内。RNN解决梯度消失的问题是采用LSTM作为基本单元。
3、过拟合
- 及时停止训练
- 增加数据
- 添加正则化项(L1和L2)
- dropout
4、欠拟合
- 增强数据
5、优化函数,使用更高效的优化算法
6、超参数的调整,学习率是认为设定的,使用自适应的学习率算法
CNN
为了减少学习参数和提取局部特征,CNN网络结构应运而生。CNN的主要特点是权值共享与局部连接,下面介绍CNN相较DNN的一些特点:
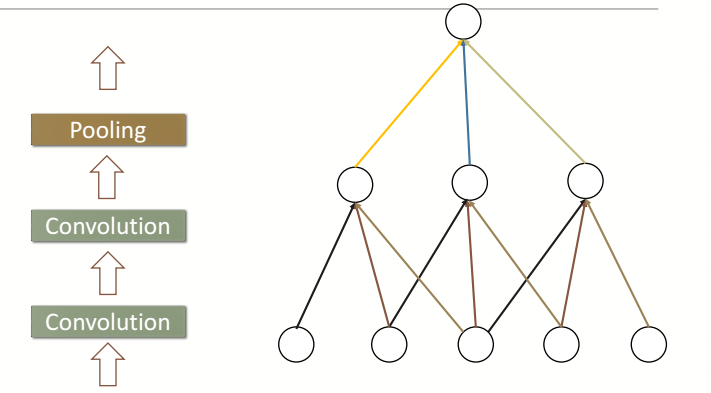
1.局部连接
我们都知道复杂的整体都是由简单的局部构成,那么如何提取到这些简单的局部特征呢?我们看下面这幅图
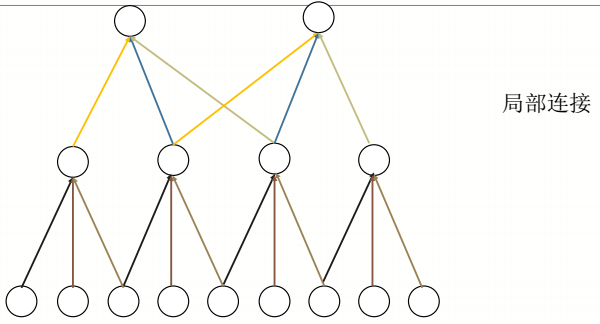 每个神经元只和其中3个神经元连接,那么较底层的神经元就提取到了较简单的局部信息,而月高层的神经元,就能提取到更复杂的特征。如下图更形象的解释了什么平面上的局部连接。
每个神经元只和其中3个神经元连接,那么较底层的神经元就提取到了较简单的局部信息,而月高层的神经元,就能提取到更复杂的特征。如下图更形象的解释了什么平面上的局部连接。
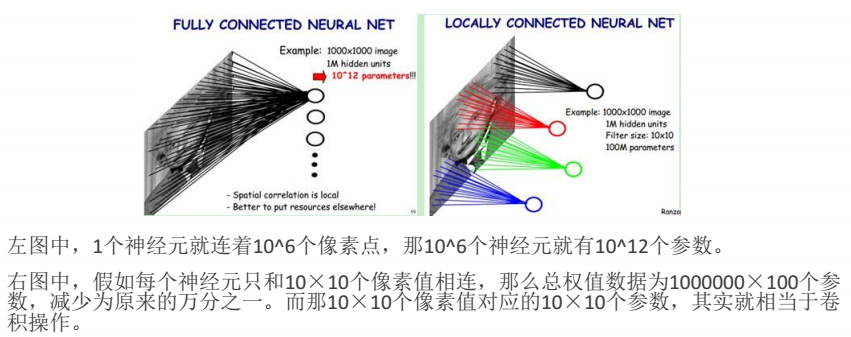
2.权值共享
CNN的权值共享说的是一个卷积核的权值在做卷积运算时是不变的,所以减少了参数个数
3.卷积与卷积核
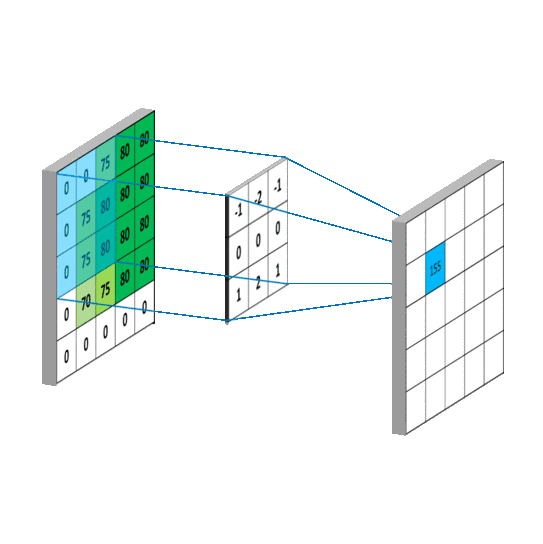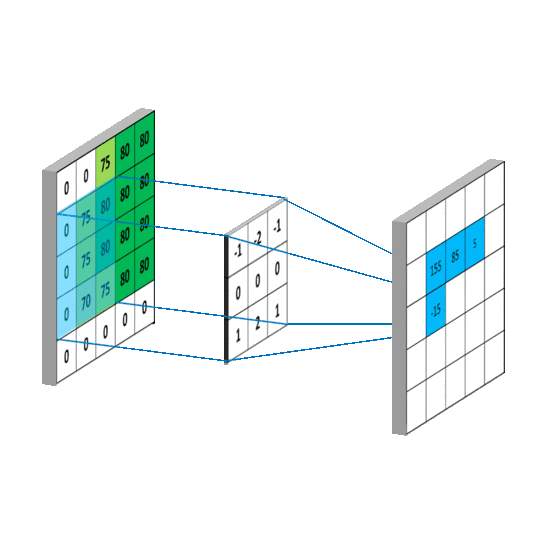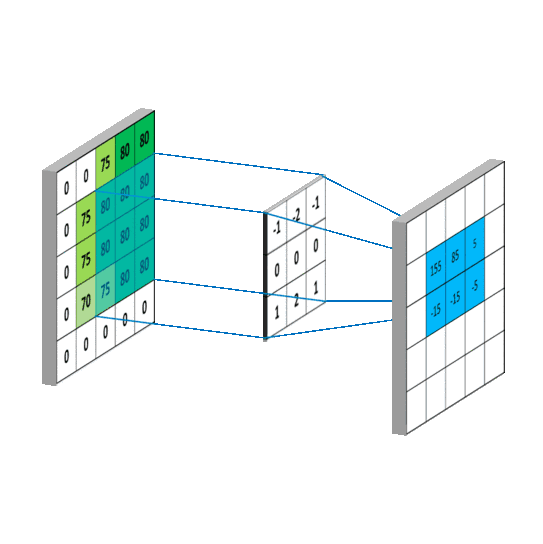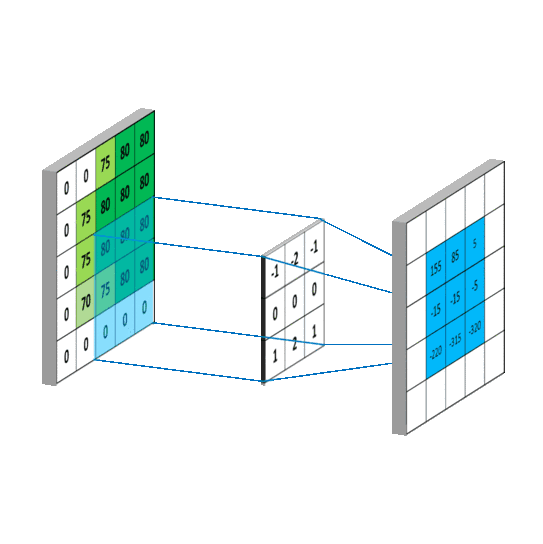 卷积公式:$y(n)=\sum_{i=-\infty}^{+\infty} x(i)h(n-i)$
tensorflow中接口:
卷积公式:$y(n)=\sum_{i=-\infty}^{+\infty} x(i)h(n-i)$
tensorflow中接口:
1
2
3
4
5
6
7
8
9
10tf.nn.conv2d(
input, # 输入
filter, # 卷积核,
strides, # 步长
padding, # ‘same’ 或者 'valid'
use_cudnn_on_gpu=True,
data_format='NHWC',
dilations=[1, 1, 1, 1],
name=None
)
举个例子: 考虑一种最简单的情况,现在有一张3×3单通道的图像(对应的shape:[1,3,3,1]),用一个1×1的卷积核(对应的shape:[1,1,1,1])去做卷积,最后会得到一张3×3的feature map。
增加图片的通道数,使用一张3×3五通道的图像(对应的shape:[1,3,3,5]),用一个1×1的卷积核(对应的shape:[1,1,1,1])去做卷积,仍然是一张3×3的feature map,这就相当于每一个像素点,卷积核都与该像素点的每一个通道做卷积。
Strides表示卷积核移动的步长。
Padding="SAME"表示要填充input使得output的shape与input的shape一致。
Padding="Valid"表示不填充,output的shape为:$\frac{I-K}{2}+1$,I表示input的size,K表示kernal_size。 动图所示为strides=1,padding='Valid'的情况。
卷积核表示卷积层训练出多少个局部特征。
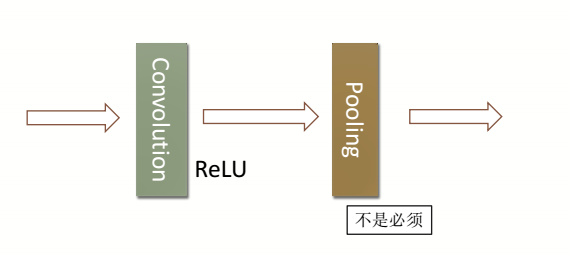
4.池化
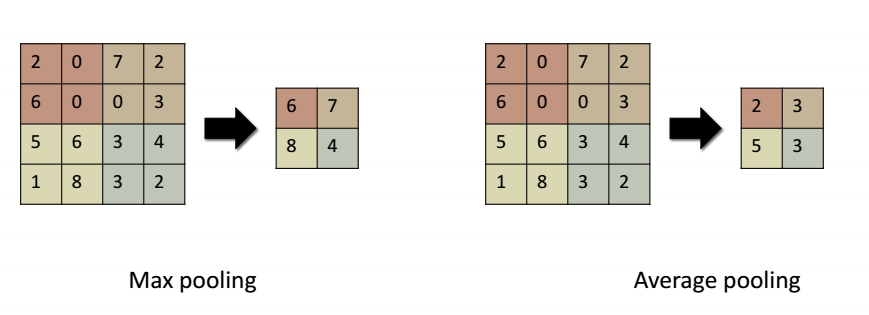 从卷积完的特征图里面选择最大(Max pooling)或者平均(Average pooling)的值作为局部特征被保留下来。
从卷积完的特征图里面选择最大(Max pooling)或者平均(Average pooling)的值作为局部特征被保留下来。
4.常见CNN结构
5.图像领域经典CNN模型
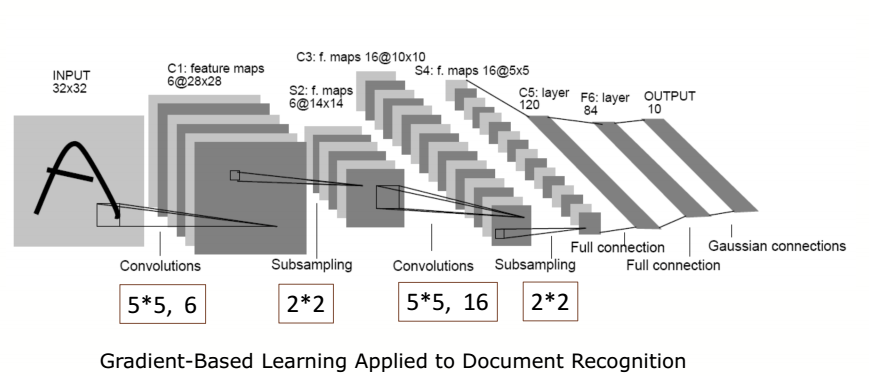
1、LeNet
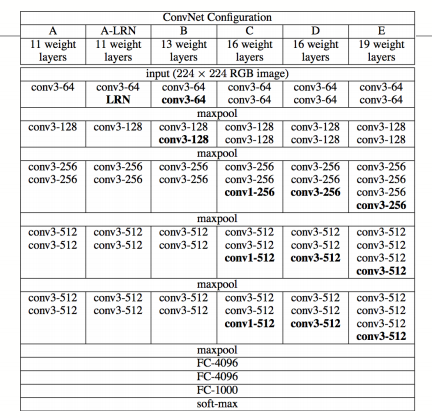
 2、VGG
2、VGG
 3、GoogLeNet inception网络结构参考
3、GoogLeNet inception网络结构参考
4、ResNet 深度残差网络参考
RNN
DNN和CNN已经在深度学习中很强了,但是他们无法解决序列到序列的训练,而RNN正是通过存储记忆来解决序列到序列的问题。
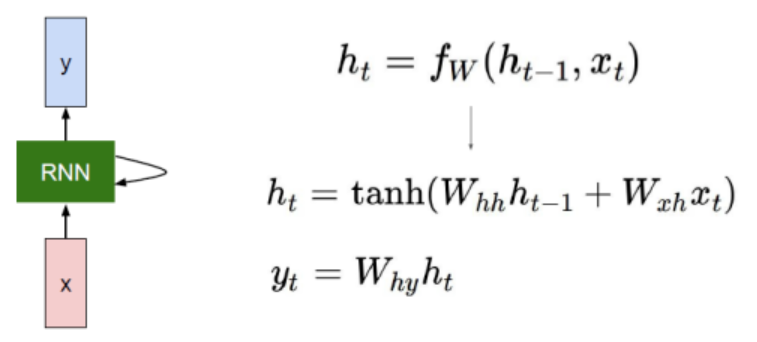 图中三个公式,
1、$h_{t}=f_w(h_{t-1}, x)$ 计算的是t时刻隐层的输出。
图中三个公式,
1、$h_{t}=f_w(h_{t-1}, x)$ 计算的是t时刻隐层的输出。
2、$h_{t}=tanh(W_{hh}h_{t-1}+W_{xh}x_{t})$,这是$h_{t}$的具体公式,其中$W_{hh}$是隐层到隐层的权重,也就是记忆,$h_{t-1}$表示的是上一时刻的记忆,$W_{xh}$表示的是输入层的权重,$x_{t}$表示t时刻的输入
3、$y_{t}$表示的是t时刻的输出,$W_{hy}$表示的是隐层到输出层的权重.
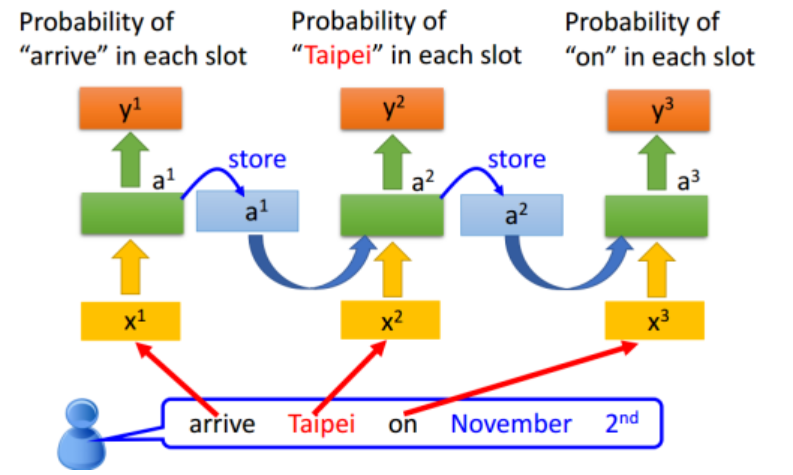
一个RNN的例子,如图:
1.RNN展开
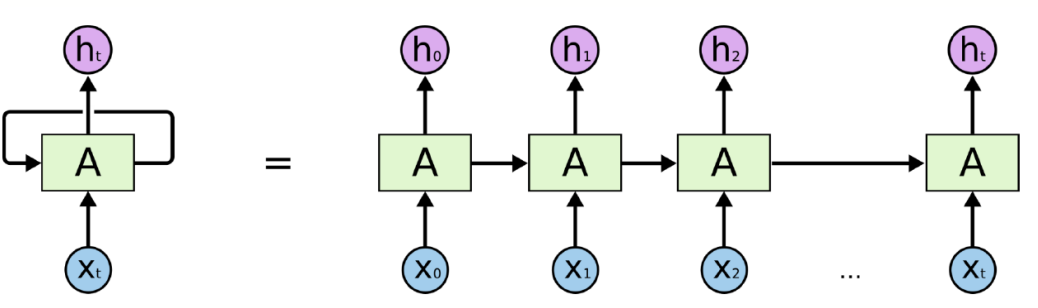 RNN单层展开指,横向展开通常称为按时间序列展开,序列数据预测问题中,预测一个序列中的下一个次,最好能知道哪些词在它前面
RNN单层展开指,横向展开通常称为按时间序列展开,序列数据预测问题中,预测一个序列中的下一个次,最好能知道哪些词在它前面
2.RNN共用权重
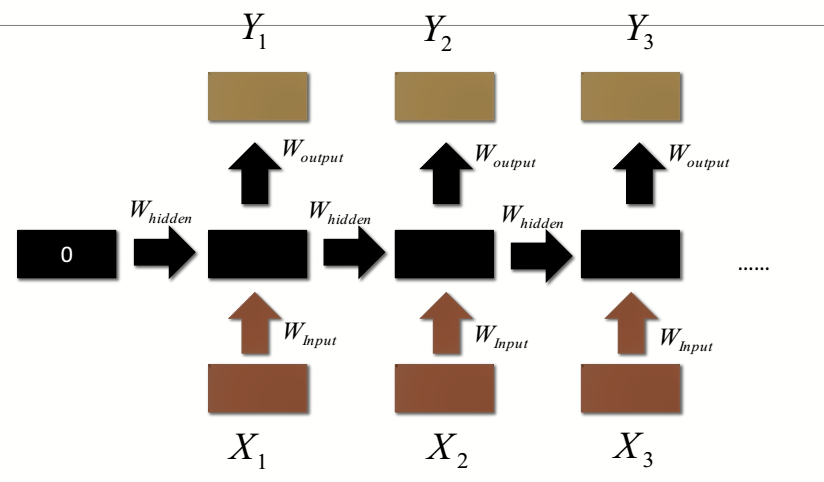 RNN按时间展开后,$W_{input}$、$W_{hidden}$和$W_{output}$都是保持一样,并不是多个,这也是为什么RNN会出现梯度爆炸的原因。
RNN按时间展开后,$W_{input}$、$W_{hidden}$和$W_{output}$都是保持一样,并不是多个,这也是为什么RNN会出现梯度爆炸的原因。
3.RNN的BP(BPTT)
RNN的反向传播是按时间序列展开的,和普通的BP算法不一样,叫随时间反向传播(BackPropagation Through Time,BPTT)。推导参考
4.RNN的不足
1、当展开一定步数后,开始输入的数据的记忆经过几次展开传递后,记忆力会衰弱。
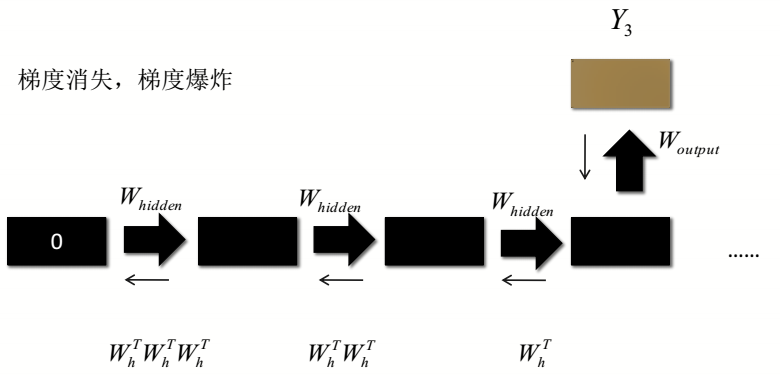 2、当RNN深度和时间序列长度过高时,很容易同时出现梯度消失于梯度爆炸。
2、当RNN深度和时间序列长度过高时,很容易同时出现梯度消失于梯度爆炸。
5.LSTM
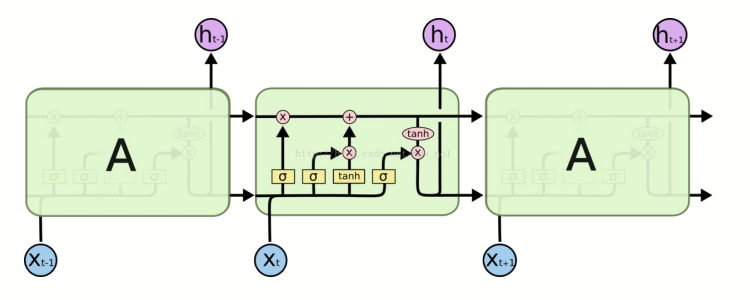 长短期记忆网络(Long Short-Term Memory)LSTM不光解决了梯度消失的问题,同时解决了普通RNN记忆力只有短期记忆的问题。
长短期记忆网络(Long Short-Term Memory)LSTM不光解决了梯度消失的问题,同时解决了普通RNN记忆力只有短期记忆的问题。
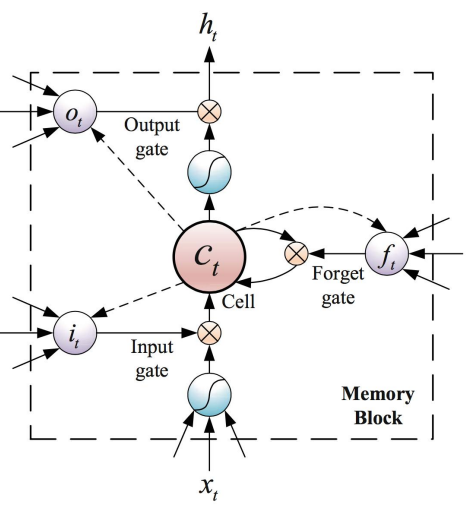 LSTM三个门:输入门,遗忘门,输出门,当$x_{t}$输入进去之后,相当于传入到4个地方,三个门以及作为数据输入,相应的公式计算,请参考这篇博客
LSTM三个门:输入门,遗忘门,输出门,当$x_{t}$输入进去之后,相当于传入到4个地方,三个门以及作为数据输入,相应的公式计算,请参考这篇博客
6.多层LSTM
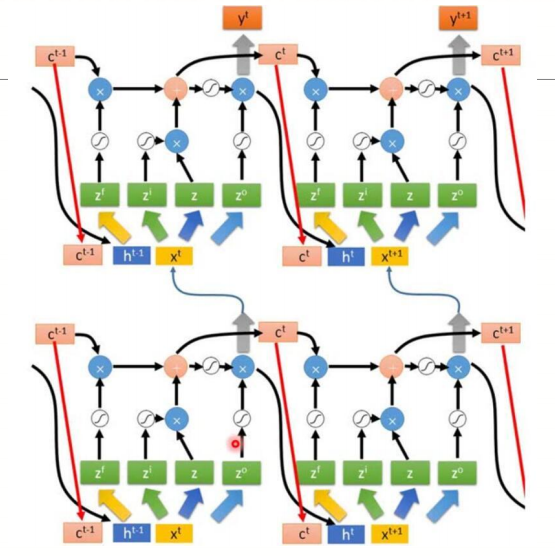
补充(Tensorflow中rnn的接口)
1
2
3
4
5
6
7rnn_size = 128 # rnn隐层节点数
num_layers = 5 # rnn层数
import tensorflow as tf
# 第一步,构建LSTM单元
decoder_cell = tf.contrib.rnn.LSTMCell(rnn_size,initializer=tf.random_uniform_initializer(-0.1, 0.1, seed=2))
# 第二步,构建多层网络
cell = tf.contrib.rnn.MultiRNNCell([get_decoder_cell(rnn_size) for _ in range(num_layers)])
RNN与CNN和DNN结构不太一样,所以在此记录一下