序列到序列模型(Seq2Seq)
RNN是一种处理序列数据的神经网络,输入是序列,输出也是序列,所有有人就提出了基于Encoder到Decoder的模型结构来处理序列到序列的应用。最基础的Seq2Seq模型包含了三个部分,即Encoder、Decoder以及连接两者的中间状态向量,Encoder通过学习输入,将其编码成一个固定大小的状态向量S,继而将S传递给Decoder,Decoder再通过对状态向量S的学习来进行输出。以下介绍两种Seq2Seq的模型结构。
1. Seq-to-Seq框架1
该模型来自于论文Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation,其结构图:
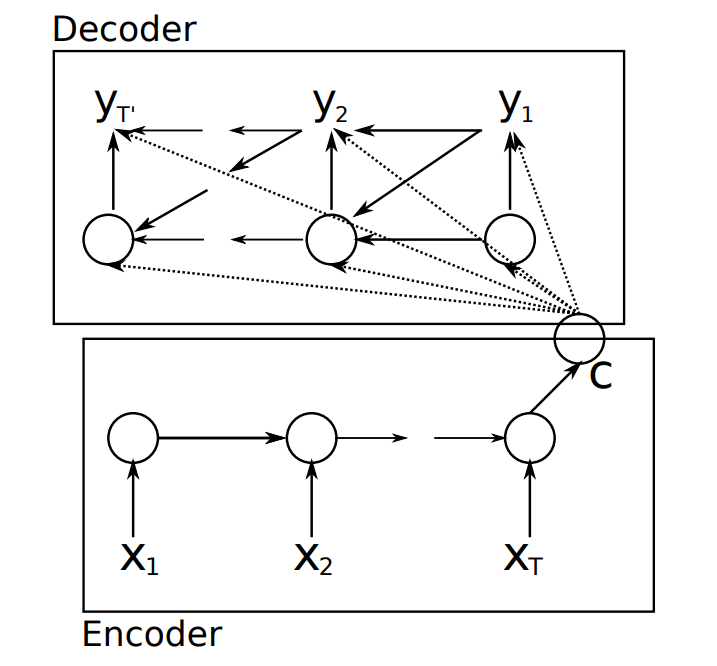 Encoder阶段将整个source序列编码成一个固定维度的向量C(也就是RNN最终隐层状态),计算公式:
$$C=\tanh(Vh^N)$$ V表示权重矩阵, $h^N$ 表示Encoder阶段最后一个输入的隐层状态(也可以理解为整个序列的编码记忆)。
Encoder阶段将整个source序列编码成一个固定维度的向量C(也就是RNN最终隐层状态),计算公式:
$$C=\tanh(Vh^N)$$ V表示权重矩阵, $h^N$ 表示Encoder阶段最后一个输入的隐层状态(也可以理解为整个序列的编码记忆)。
Decoder也是一个RNN网络, $C$ 作为初始化隐层状态传入(理解为将Encoder序列解码),其隐层状态 $h$ 的计算公式: $$h_t = f(h_{t-1}, y_{t-1}, C)$$ 其中 $h_{t-1}$ 和 $y_{t-1}$ 表示前一时刻隐层值和输出值,而 $y_t$ 的结果就和普通神经网络结果一样,在RNN后面接入fc层和softmax层,求最大概率。
2. Seq2Seq框架2
该模型来自于论文Sequence to Sequence Learning with Neural Networks,其模型结构:
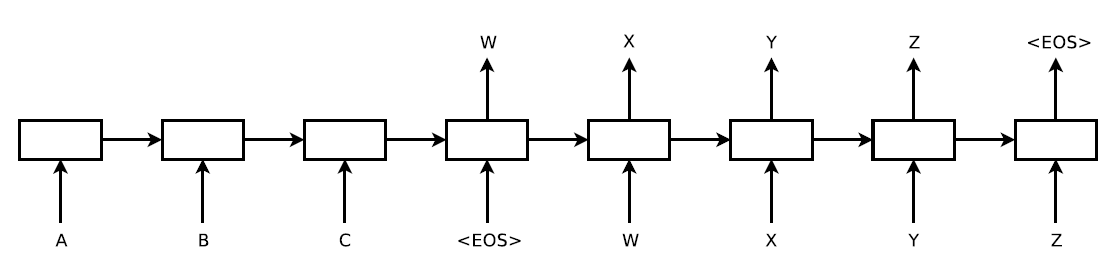 与上一模型不同的是,其source编码后的向量C直接作为Decoder阶段RNN的初始化state,而不是在每次Decoder时都作为RNN的输入,此外,Decoder训练时RNN的输入是target(目标值),而不是前一时刻的输出,训练示意图
与上一模型不同的是,其source编码后的向量C直接作为Decoder阶段RNN的初始化state,而不是在每次Decoder时都作为RNN的输入,此外,Decoder训练时RNN的输入是target(目标值),而不是前一时刻的输出,训练示意图
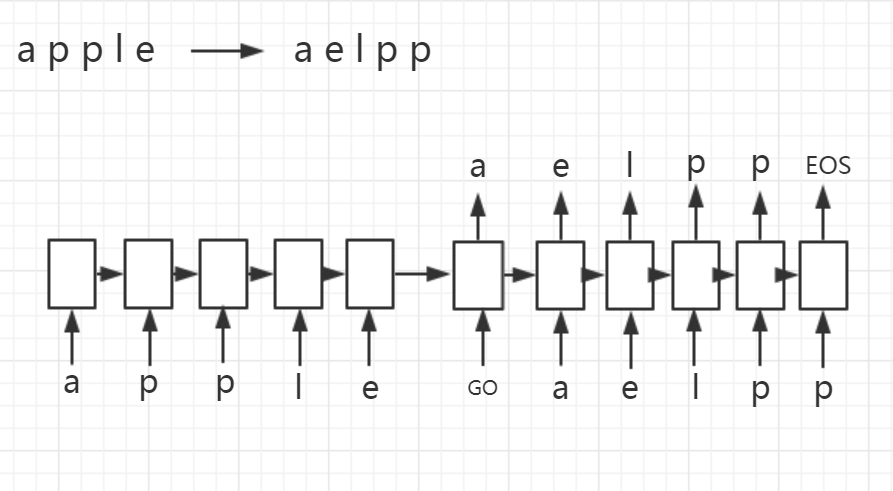 解码示意图
解码示意图
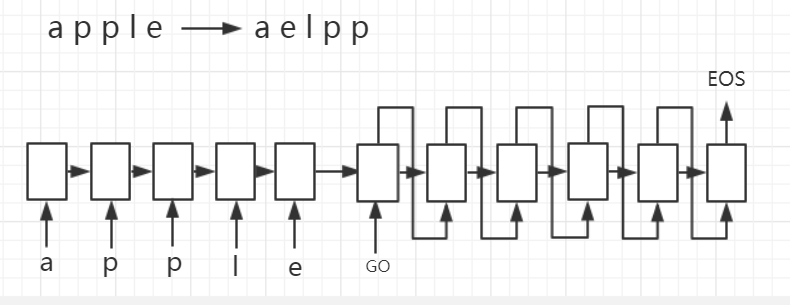
3. Seq2Seq实战
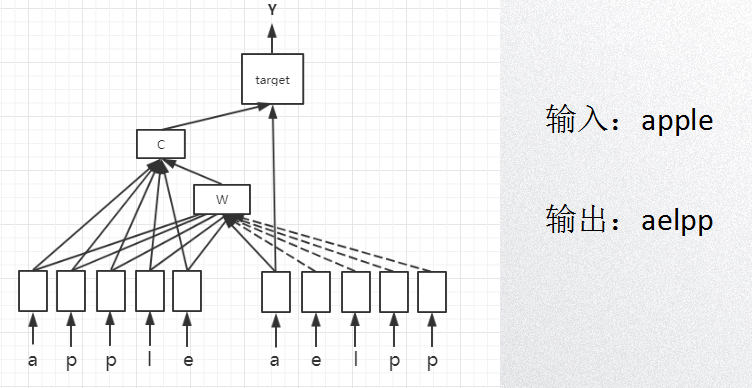
利用TensorFlow来构建一个基础的Seq2Seq模型,通过向我们的模型输入一个单词(字母序列),例如apple,模型将按照字母顺序排序输出,即输出aelpp。
数据集包括source和target,共10000条:
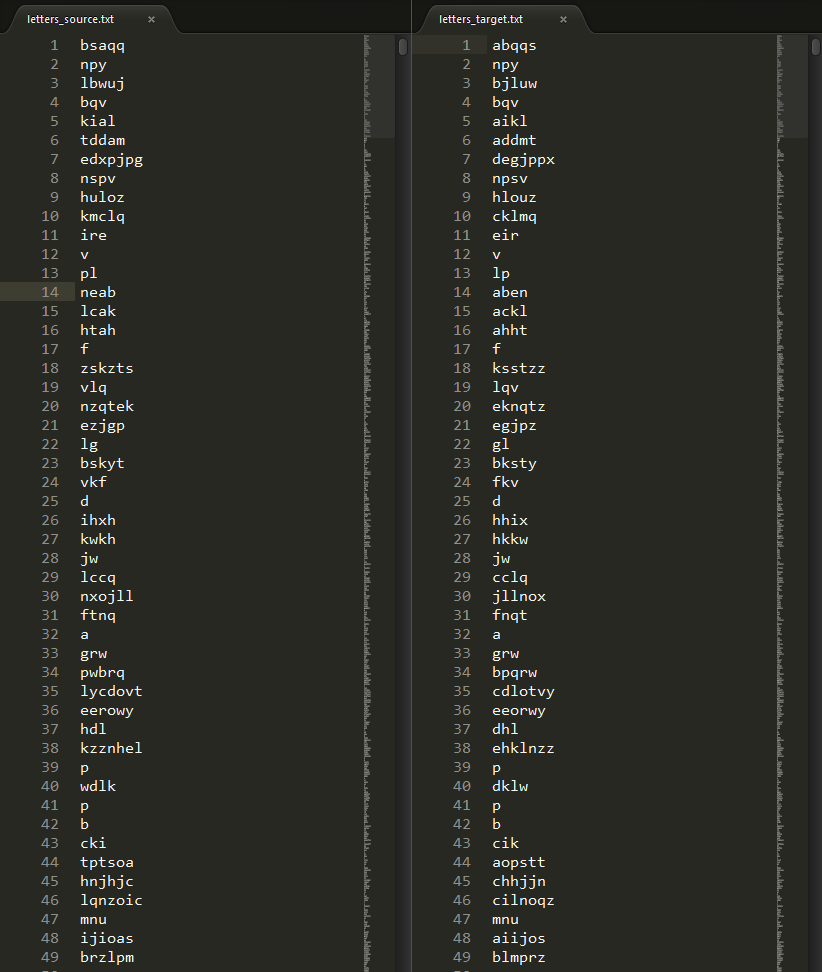 开发步骤:
开发步骤:
- target数据处理,结果为[GO, x, y, z, EOS, PAD],当然输入不能为字符,所以我们需要建立一个ch2idx和idx3ch的关系
- gen_batch,一般我们都是一个batch这样一起训练
- 构建Encoder网络
- 构建Decoder网络(其中包含train和test的不同结构)
- 连接Encoder和Decoder,组成Seq2Seq模型
- Running和predicting
解释一下Seq2Seq框架2中加GO,EOS和PAD的原因,其目的就是告诉Decoder什么时候开始,什么时候结束,真正训练的时候,EOS并没有作为输入传递给RNN,因此我们需要将target中最后一个字符(EOS)去掉,同时还需要再前面加上开始标识(GO)。因为我们是batch一起训练,动态RNN展开,每一个batch需要固定序列长度,所以我们要加PAD。
4. 源码
该实验是用jupyter实现的,python3.6,tenserflow1.8
Attention
1. Seq2Seq思考
- Encoder将输入编码为固定大小状态向量,是一个”信息有损压缩“的过程, 信息量越大,那么损失的信息就越多。
- 随着sequence length的增加,意味着时间维度上的序列很长,RNN模型 会出现梯度弥散
- 基础的模型连接Encoder和Decoder模块的组件仅仅是一个固定大小的状 态向量,Decoder无法直接去关注到输入信息的更多细节
既然Seq2Seq有这些劣势,那么要如何解决呢,答案就是Attention。
2. 什么叫注意力机制(Attention-based mechanism)?
注意到Decoder设计中,各个时刻都使用相同的记忆C,我们自然想到了可以在不同的时刻采用不同的记忆C,结构如下
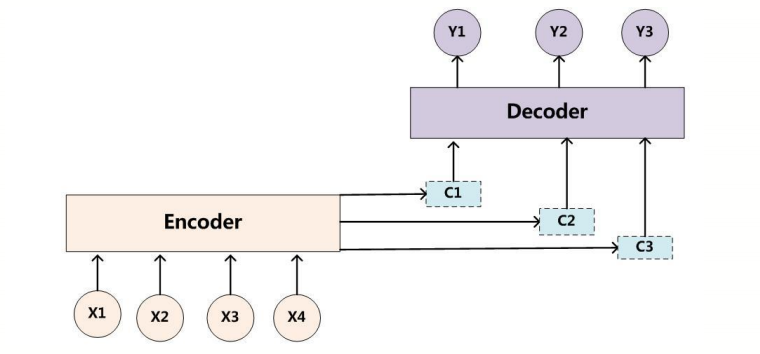 以下介绍两种简单的Attention结构。
以下介绍两种简单的Attention结构。
3. Attention结构1
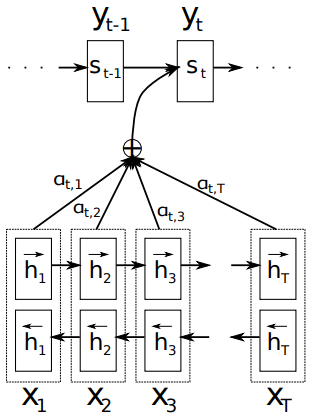
该模型来自于论文 Neural Machine Translation by Jointly Learning to Align and Translate,其模型结构如下
 Attention是为了得到不同时刻的C,那么我们从公式角度来看不同时刻C的计算过程:
Attention是为了得到不同时刻的C,那么我们从公式角度来看不同时刻C的计算过程:
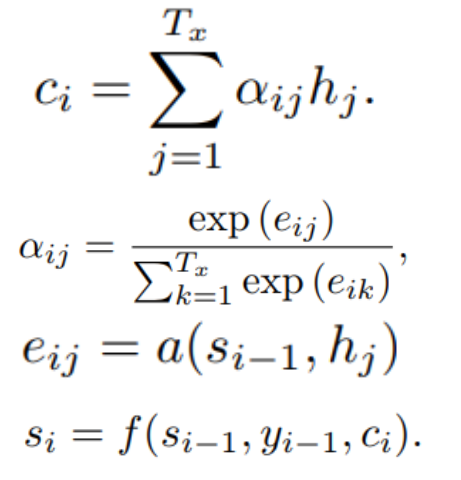 解释如下: $h_j$ 表示的是Encoder的隐层记忆, $s_i$表示Decoder结构中 $i$ 时刻的隐层记忆。公式从下往上看
解释如下: $h_j$ 表示的是Encoder的隐层记忆, $s_i$表示Decoder结构中 $i$ 时刻的隐层记忆。公式从下往上看
- $s_i$ 是由 $s_{i-1}, y_{i-1}, c_i$ 三个值计算出来,分别表示Decoder上一时刻隐层记忆、输出和当前时刻的记忆
- 计算 $c_i$ 需要计算 $\alpha_{ij}$ 和 $e_{ij}$
- $e_{ij}$ 通过 $s_{i-s}, h_j$ 计算得来,那么计算方法 $a$ 可以用一个小型的神经网络来逼近
- 计算 $\alpha_{ij}$ 可以用一个类似softmax的方法用 $e_{ij}$ 计算得来
通过这种计算,在Decoder过程中,每个时刻的 $s_i$ 都可以计算出对应的 $c_i$ ,训练和预测的方法和Seq2Seq的方式一样。
4. Attention结构2
该模型来自于论文 Effective Approaches to Attention-based Neural Machine Translation,结构如图
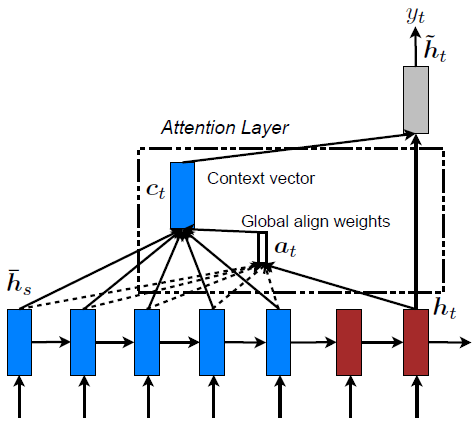 模型公式如下:
模型公式如下:
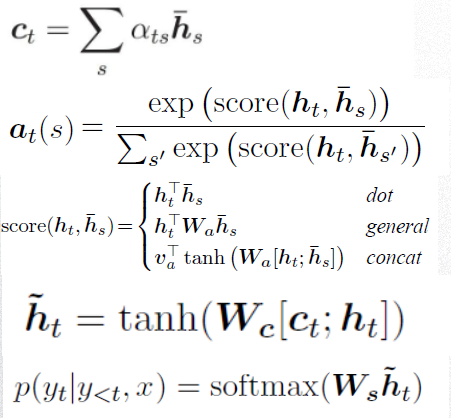 公式解释:同样是要 $c_t$ ,只是计算方式不同,这里指的是 $score$ 这个函数,一般有三种计算方式,论文指出general的方式取得了比较好的结果,看公式:
$$socre(h_t, \bar h_s) = h_t^{\top} W_a \bar h_s$$
表示的是Decoder的隐层记忆 $h_t^{\top}$ 与 Encoder的隐层记忆 $\bar h_s$ 通过一个注意力权重 $W_a$ 连起来,表示从target到source的映射关系,这个权重可以在训练过程中学习得到。
公式解释:同样是要 $c_t$ ,只是计算方式不同,这里指的是 $score$ 这个函数,一般有三种计算方式,论文指出general的方式取得了比较好的结果,看公式:
$$socre(h_t, \bar h_s) = h_t^{\top} W_a \bar h_s$$
表示的是Decoder的隐层记忆 $h_t^{\top}$ 与 Encoder的隐层记忆 $\bar h_s$ 通过一个注意力权重 $W_a$ 连起来,表示从target到source的映射关系,这个权重可以在训练过程中学习得到。
5、加入Attention的Seq2Seq如何实现?
Tensorflow提供了很多种Attention的API,这里我们使用第二种Attention的方式,官方示例如下:
 接入Decoder的解码过程
接入Decoder的解码过程
 模型实现示例图
模型实现示例图
 结果
结果
 预测
预测

6、源码
加入Attention的实现是在基础Seq2Seq上改进得来,也是jupyter版本。
总结
- 加入Attention的seq2seq有很多应用场景,在翻译领域取得了较好结果
- Attention的变形有很多,需要进一步研究
- Attention的一个最要优点就是可视化注意力权重,这里没用做